- 제출방법 : 프로젝트 수행 후 전체 디렉토리를 ‘hw2.zip’라는 이름의 파일로 압축하여 Uclass 과제 게시판에 업로드해주세요.
- 제출기한 : 4월 14일 월요일 11:59pm
과제 진행 시 어려운 점이 있으면 Ed Discussion 게시판을 이용해 질문하세요. 게시판을 통해 하기 어려운 질문이라면 아래 TA 이메일을 통해 문의하시기 바랍니다.
- TA 이메일: seongminkim16@gmail.com
구현할 언어(K0)의 문법
<program> ::= <expression>
<expression> ::= <natural_number> <binary_operator> <natural_number>
<binary_operator> ::= + | - | * | /
<natural_number> ::= i, i ∈ ℕ₀ (0을 포함한 자연수)
이번 과제에서는 아주 간단한 프로그래밍 언어를 구현합니다. 이 언어로 짜여진 프로그램은 하나의 표현식을 가질 수 있습니다. 하나의 표현식은 0을 포함한 자연수 두 개를 입력 받아 사칙 연산을 수행합니다. 이 언어를 K0라고 부르겠습니다.
이 언어로 표현 가능한 프로그램들은 다음이 있습니다.
3 + 20 - 23423 * 1252 / 320 / 0
utop # K0.Interpreter.execute "3 + 2";;
Result: 5
- : unit = ()
utop # K0.Interpreter.execute "0 - 234";;
Result: -234
- : unit = ()
utop # K0.Interpreter.execute "23 * 12";;
Result: 276
- : unit = ()
utop # K0.Interpreter.execute "52 / 3";;
Result: 17
- : unit = ()
utop # K0.Main.execute "20 / 0";;
Exception: Failure "Division by zero".
이 CFG로 표현 불가능한 프로그램들은 다음이 있습니다.
+ 2420/ 2 3"University of Seoul"
utop # K0.Main.execute "+ 2";;
Exception: Failure "Invalid expression format".
utop # K0.Main.execute "420";;
Exception: Failure "Invalid expression format".
utop # K0.Main.execute "/ 2 3";;
Exception: Failure "Expected integer operands".
utop # K0.Main.execute "University of Seoul";;
Exception: Failure "Unexpected character in input".
인터프리터 언어의 흐름
K0를 인터프리터 기법을 통해서 구현해봅시다. 인터프리터는 프로그래밍 언어로 작성된 소스 코드를 한 줄씩 또는 한 구문씩 읽어서 바로 실행하는 프로그램입니다. 이 과정은 일반적으로 다음과 같은 선형적 구조를 거쳐서 실행됩니다.

어휘 분석기(Lexer)
어휘 분석기(Lexer)는 여러분의 소스 코드를 받아 “토큰(token)”이라고 하는 조각으로 나눕니다. 토큰은 그 자체로 식별할 수 있는 소스 코드의 작은 단위입니다. 예를 들면, 숫자, 수학 연산자, 변수 이름, 그리고 키워드(if나 for 같은)를 위한 토큰들이 있습니다.
구문 분석기(Parser)
구문 분석기(Parser)는 그 순차적인 토큰 배열을 가져와 트리 구조로 재구성합니다(AST의 T는 Tree, 즉 트리를 나타냅니다). 이 트리가 바로 토큰들에 의미를 부여하며, 내용을 파악하고 작업하기 더 쉬운 좋은 구조를 제공해 줍니다.
Interpreter
마지막으로, 인터프리터는 구문 분석기가 생성한 AST를 순회(traverse)하면서 코드의 의미를 해석하고 실행합니다. 즉, AST의 각 노드(node)를 방문하며 해당 노드가 나타내는 연산(덧셈, 변수 할당, 조건문 평가, 함수 호출 등)을 실제로 수행하는 것입니다. 인터프리터는 이 트리 구조를 따라가며 프로그램의 로직을 한 단계씩 실행하고, 그 결과를 즉시 반영합니다. 컴파일러처럼 전체 코드를 기계어로 미리 변환하는 과정 없이, 해석과 실행이 동시에 이루어지는 것이 특징입니다.
어휘 분석기(Lexer)
어휘 분석기(Lexer)는 소스 코드를 받아 관련 있다고 식별되는 소스 코드 조각들인 토큰(token)의 순차적인 배열(linear sequence)을 생성합니다.
Token types
자연수의 사칙연산을 지원해야 하므로, 5가지 종류의 토큰이 필요합니다:
- 정수를 나타내는 토큰 타입
- ’+’ 연산자를 위한 토큰 타입
- ’-‘ 연산자를 위한 토큰 타입
- ‘*’ 연산자를 위한 토큰 타입
- ’/’ 연산자를 위한 토큰 타입
또한 프로그램의 끝을 나타내는 마지막 토큰도 필요하며, 이를 EOF(end-of-file의 약자)라고 부를 것입니다.
type token_type =
| INT
| PLUS
| MINUS
| TIMES
| DIVIDE
| EOF
“token” 타입은 record를 사용하여 구현합니다. 각 토큰은 token type과 token value를 가집니다. 이때, 연산자를 나타내는 토큰 타입아나 EOF를 나타내는 토큰 타입은 값이 없기에 token_value의 타입은 int option으로 설정합니다.
type token = {
token_type: token_type;
token_value: int option;
}
lexer.ml
type token_type =
| INT
| PLUS
| MINUS
| TIMES
| DIVIDE
| EOF
type token = {
token_type: token_type;
token_value: int option;
}
let rec skip_whitespace code index =
if index >= String.length code then
index
else
match code.[index] with
| ' ' | '\t' | '\n' | '\r' -> skip_whitespace code (index + 1)
| _ -> index
let is_digit c =
match c with
| '0' .. '9' -> true
| _ -> false
let read_integer code index =
let start_index = index in
let rec read_digits current_index =
if current_index >= String.length code then
current_index
else if is_digit code.[current_index] then
read_digits (current_index + 1)
else
current_index
in
let end_index = read_digits index in
let num_str = String.sub code start_index (end_index - start_index) in
int_of_string num_str, end_index
let tokenize code =
let rec next_token_state index =
let current_index = skip_whitespace code index in
if current_index >= String.length code then
[{ token_type = EOF; token_value = None }]
else
match code.[current_index] with
| '+' -> { token_type = PLUS; token_value = None } :: next_token_state (current_index + 1)
| '-' -> { token_type = MINUS; token_value = None } :: next_token_state (current_index + 1)
| c when is_digit c -> begin
match read_integer code current_index with
| (value, next_index) -> { token_type = INT; token_value = Some value } :: next_token_state next_index
end
| _ -> failwith "Unexpected character in input"
in next_token_state 0
let print_token token =
match token with
| { token_type = INT; token_value = Some v } -> Printf.printf "%d " v
| { token_type = PLUS; token_value = None } -> Printf.printf "Plus "
| { token_type = MINUS; token_value = None } -> Printf.printf "Minus "
| { token_type = TIMES; token_value = None } -> Printf.printf "Times "
| { token_type = DIVIDE; token_value = None } -> Printf.printf "Divide "
| { token_type = EOF; token_value = None } -> Printf.printf "EOF\n"
| _ -> failwith "Unknown token type"
let tokenize_and_print code =
let token_sequence = tokenize code in
List.iter print_token token_sequence
어휘 분석기는 여러분의 코드가 유효한지 전혀 신경쓰지 않습니다. 어휘 분석기는 + 3 5나 3 3 3 + 5 5 5 - - -같은 프로그램도 토큰화할 수 있습니다. 어휘 분석기가 토큰화한 프로그램이 유효한지는 구문 분석기가 검증하게 됩니다.
utop # tokenize_and_print "+ 3 5";;
Plus 3 5 EOF
- : unit = ()
utop # tokenize_and_print "3 3 3 + 5 5 5 - - -";;
3 3 3 Plus 5 5 5 Minus Minus Minus EOF
- : unit = ()
구문 분석기(Parser)
구문 분석기(Parser)는 우리 프로그램에서 토큰 스트림(stream)을 받아 그것들이 (문법적으로) 의미가 통하는지 확인하는 부분입니다.
예를 들어, 이전 섹션에서 어휘 분석기는 "3 + 5" 코드 문자열과 "3 3 3 + 5 5 5 - - -" 코드 문자열을 똑같이 받아들인다는 것을 확인했습니다. 하지만 구문 분석기의 경우는 다릅니다. 구문 분석기는 "3 + 5"에 대한 토큰들을 보고 두 정수의 덧셈으로 인식하겠지만, "3 3 3 + 5 5 5 - - -" “코드”를 나타내는 토큰 스트림을 받으면 (문법 오류를) 보고할 것입니다.
하지만 구문 분석기는 그보다 조금 더 많은 일을 합니다. 구문 분석기는 토큰 배열이 (문법적으로) 의미가 통하는지 확인할 뿐만 아니라, 그 토큰들을 사용하여 트리 형태의 또 다른 코드 표현(representation)을 만들어냅니다.
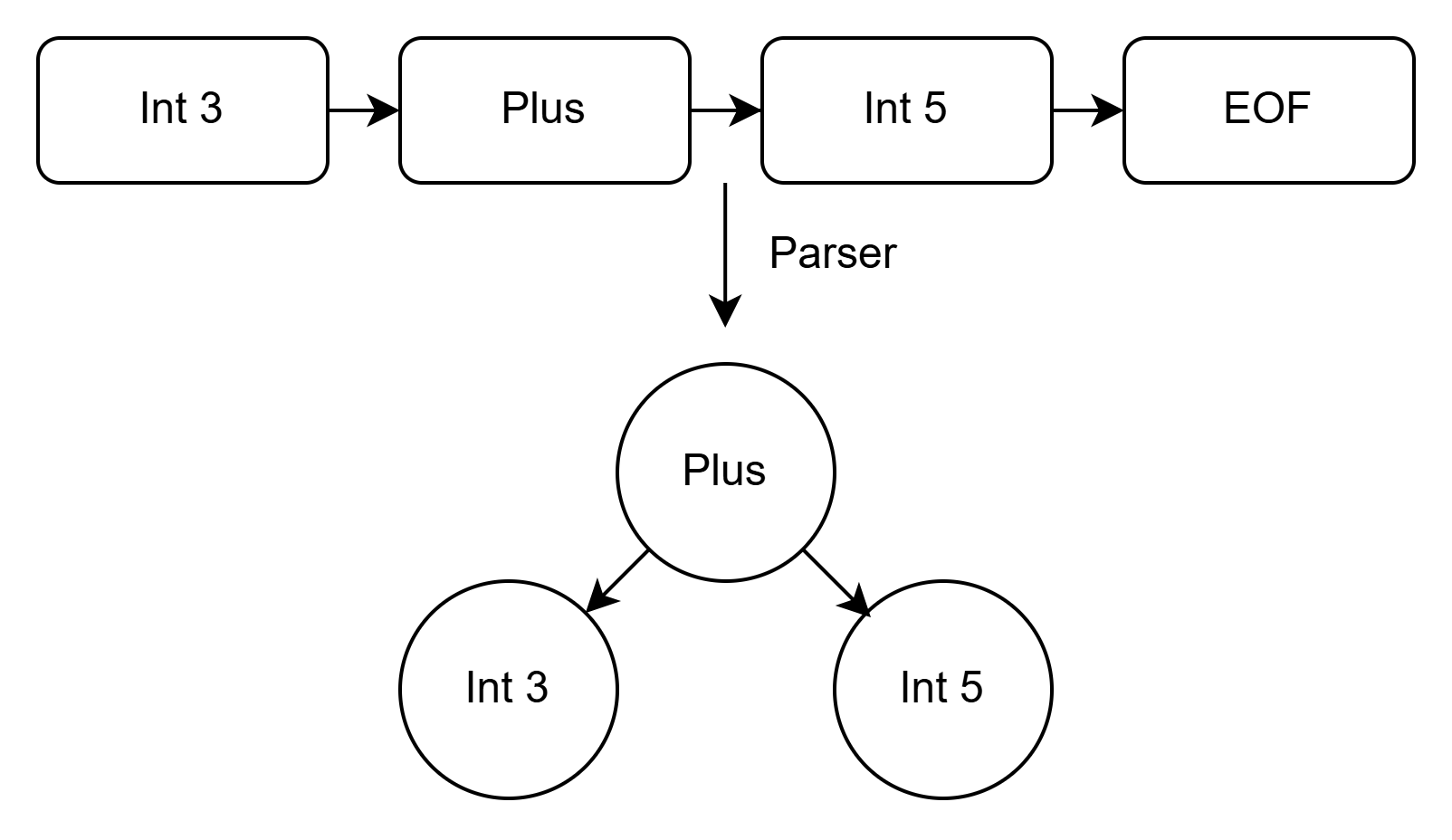
예를 들어, 3 + 5를 tokenize하면 다음과 같은 토큰 리스트를 얻습니다.
3 Plus 5 EOF
구문 분석기는 이를 트리 형태로 변환합니다.
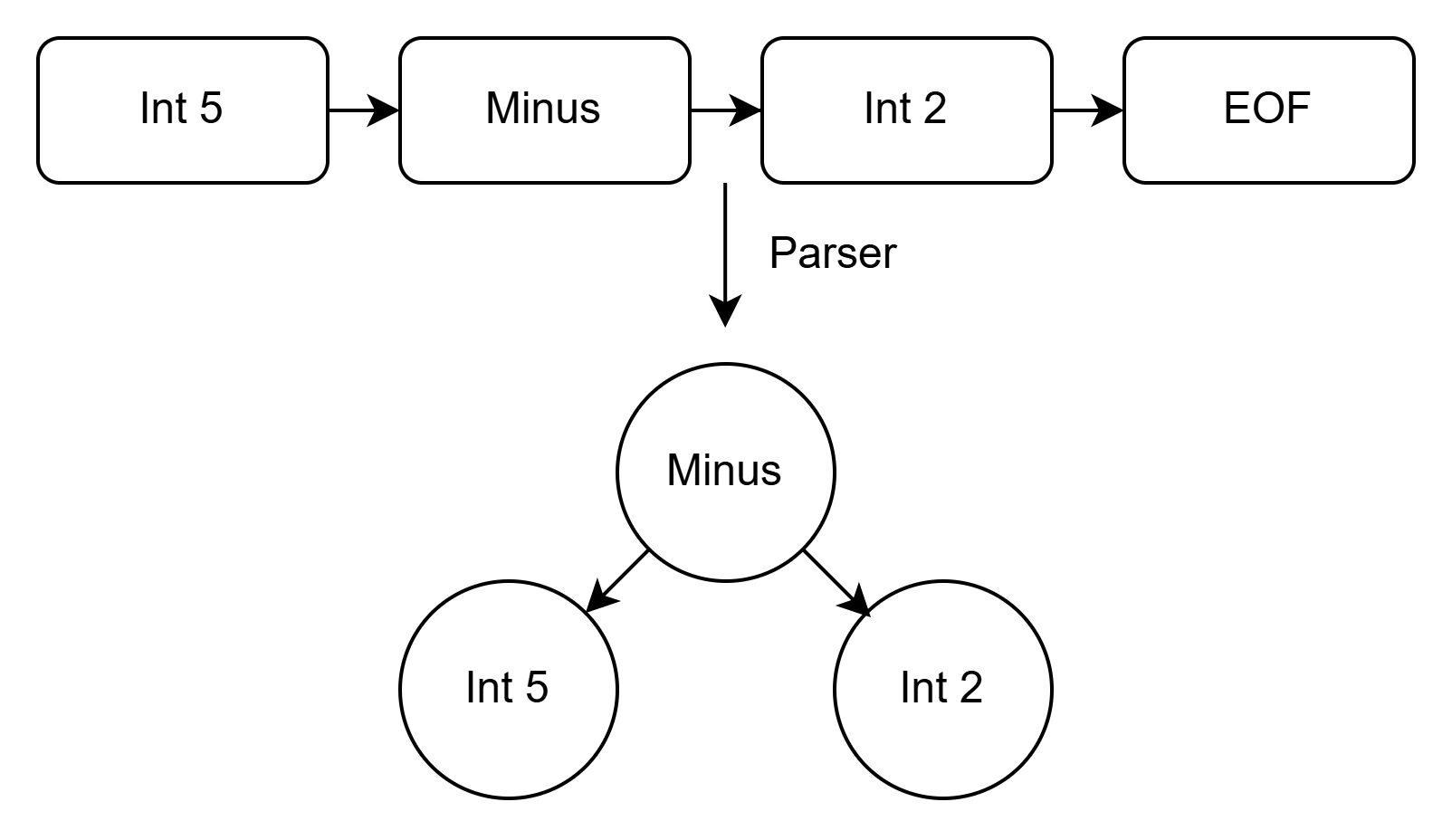
5 - 2를 tokenize하면, 다음과 같은 토큰 리스트를 얻습니다.
5 Minus 2 EOF
구문 분석기는 이를 트리 형태로 변환합니다.
Abstract Syntax Tree (AST)
우리가 만드는 이 트리가 바로 추상 구문 트리(Abstract Syntax Tree, AST)라고 부르는 것입니다. 이것이 추상 구문 트리인 이유는, 연산을 작성하는 데 사용된 원래의 구문(syntax)에는 신경 쓰지 않는 트리 표현이기 때문입니다. 이것은 오직 우리가 수행할 연산에만 관심을 가집니다.
예를 들어, 우리 언어가 전위 표기법(prefix notation)을 사용하도록 결정했다고 가정해 봅시다. 그러면 덧셈은 이제 + a b로, 뺄셈은 - a b로 표현될 것입니다.
이제 어휘 분석기는 토큰을 다른 순서로 생성하겠지만, 구문 분석기는 여전히 동일한 트리를 만들 것입니다. 왜 그럴까요? 왜냐하면 구문 분석기는 코드가 어떻게 작성되었는지가 아니라, 코드가 무엇을 하는지에만 관심을 갖기 때문입니다.
ast.ml
type binary_operator =
| Add
| Sub
| Mult
| Div
type expression = Binary_Operation of binary_operator * int * int
parser.ml
open Lexer
open Ast
let get_token_value = function
| { token_value = Some value; _ } -> value
| { token_value = None; _ } -> failwith "Token has no value"
let parse = function
| left_operand :: operator :: right_operand :: [eof] -> begin
if left_operand.token_type <> INT || right_operand.token_type <> INT then
failwith "Expected integer operands"
else if eof.token_type <> EOF then
failwith "Expected EOF at the end of expression"
else
let left_operand = get_token_value left_operand in
let right_operand = get_token_value right_operand in
match operator.token_type with
| PLUS -> Binary_Operation (Add, left_operand, right_operand)
| MINUS -> Binary_Operation (Sub, left_operand, right_operand)
| _ -> failwith "Unexpected operator"
end
| _ -> failwith "Invalid expression format"
번역기(Interpreter)
interpreter.ml
open Ast
let eval = function
| Binary_Operation (Add, left, right) -> left + right
| Binary_Operation (Sub, left, right) -> left - right
let execute (s : string) =
let tokens = Lexer.tokenize s in
let ast = Parser.parse tokens in
let program_result = eval ast in
Printf.printf "Result: %d\n" program_result
프로젝트 구성
seongminkim@DESKTOP-J8E2UER:~/ocaml/K0$ tree
.
├── dune-project
└── src
├── ast.ml
├── dune
├── interpreter.ml
├── lexer.ml
└── parser.ml
dune-project
(lang dune 2.9)
src/dune
(library
(name K0))
Debug / Test
dune utop src
수행할 과제
- 주어진
lexer.ml,parser.ml그리고interpreter.ml파일을 수정하여 곱하기와 나누기 연산을 K0 언어에 추가하세요.